
This post introduces a framework to represent the mathematical concept of probability in Python. We’ll develop tools over a series of posts that we can use to analyze games of chance and some popular board games. We will also show how to apply these ideas to uncertainty in sports.
A Jupyter Notebook with the code and portions of the text from this post may be found here.
We’ll start by analyzing familiar examples such as coin flips, dice rolls, and a shuffled deck of playing cards.
These examples are commonly used in teaching probability, because most people have good physical intuition for these random processes. We will analyze these processes (and the games which use them) using the rules of classical probability. As the great French astronomer and mathematician Pierre-Simon, marquis de Laplace wrote in 1812:
The probability of an event is the ratio of the number of cases favorable to it, to the number of all cases possible when nothing leads us to expect that any one of these cases should occur more than any other, which renders them, for us, equally possible.
If we assume that the coins, dice and cards are fair, we can assume all possible outcomes are equally likely. That’s because of the (assumed) physical symmetry of of the objects. A fair coin has a 
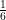
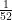
Notice that in the coin and die example, we’re assuming away any “impossible” outcomes such as the coin balancing exactly on its edge, or the die balancing on a corner with no side facing up. Our physical intuition says these things are so unlikely that we are very safe ignoring them. If people want to play Monopoly or flip coins in outer space, they will need to rethink things.
Furthermore, serious scientific testing in 2007 revealed that coins that are caught in midair actually seem to come up with the same side showing as before the flip around 51% of the time. We will put aside the question of whether a possible 51-49 bias (versus the assumed 50-50) matters in the real world, at least for now. The good news is that if you allow the coin to bounce on a hard surface, it’s much closer to 50-50.
There’s a lot more we could discuss about the philosophical aspects of probability, and the limitations of the classical approach, but let’s move on to some practical aspects of probability modeling. Over the course of these posts, you’ll see that we can answer some interesting and useful questions about games of chance and popular board games. We’ll also be able to extend this probability framework to better understand uncertainty in sports. We will incorporate some of the more complex probability concepts, and some of the tricks and pitfalls, down the road as we need them.
The Python framework used in these posts is inspired by and borrows from two excellent sources: Peter Norvig’s Concrete Introduction to Probability using Python and Allen Downey’s blog post on using the Python Counter class to represent probability mass functions. I highly recommend these two sources to you, and hope that you find the approach I’ve taken here combines some of the best aspects of each.
The Essentials of Classical Probability
Here is a list of the basic things to keep in mind about classical probability modeling:
- There are a finite number of discrete possible outcomes.
- Because they are finite and discrete, the outcomes can be written down in a list called the sample space and counted (although this may be cumbersome to do in practice, since the number of possible outcomes may be very large, as we’ll soon see). The sample space must have at least two possible outcomes for there to be any uncertainty.
- We are going to conduct an experiment (e.g., flipping a coin), which has an uncertain outcome that we are going to observe.
- The outcomes are mutually exclusive and exhaustive, meaning one and only one of the outcomes will occur in the experiment, and an event outside the sample space cannot occur. The coin either lands heads or tails, but not both. It also doesn’t float away (as in outer space) or land on its edge, which would count as neither.
- The random process of the experiment (e.g., the coin and how it is flipped) is fair, so that each of the possible outcomes is equally likely.
- An event is a set of one or more outcomes that we want to study (e.g., the coin lands heads, or a six-sided die roll is higher than 3).
- The classical probability of an event is just the fraction with numerator [number of outcomes from the sample space in the event] and denominator [number of outcomes in the sample space].
The standard math symbol for the probability of some event 
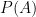
All this machinery just makes precise what we already intuitively know:
(fair coin lands heads) =
=
. Here, the experiment is a die roll, and the event is a set of two outcomes {4, 5}.
=
. Here, the experiment is a draw from a deck, and the event is a set of thirteen possible outcomes {2-10, J, Q, K, A, all of hearts}.
= 1.
The benefit of the mathematical machinery is that it lets us think clearly and consistently about more complicated situations with much larger numbers of potential outcomes.
Counting
Although fair coins, dice and playing cards are very simple random processes, you will see how the number of possible outcomes can quickly become very large, even for some relatively simple games.
One of the trickiest aspects of probability modeling is accurately keeping track of the possible outcomes, and counting which ones are in the event you’re interested in studying. Keeping track of the outcomes becomes tedious and error-prone: exactly the right job for a computer!
If you look at probability and statistics textbooks, you’ll see a lot of complicated formulas, which were developed before the era of electronic calculation. Very smart people used advanced mathematics to develop these formulas, along with approximations and numerical tables to allow people working with pencil and paper to grind through problems.
You’ll see that letting the computer keep track of the outcomes allows you to easily analyze situations which theoretically have millions of possible outcomes, such as five card draw, which has almost 2.6 million possible hands. Other variants of poker have many more possible outcomes.
This is not to say that the advanced math is now useless because of computers; far from it. Combining math with computers allows for the solution of complex probability and machine learning problems that would make simplistic computer programs choke or crash. It’s just that counting huge numbers is hard for people, and the simpler computer methods can give better intuition and help sanity-check the results. Our goal is to learn how to practically apply both the math and computer modeling to get useful answers quickly and intuitively.
Representing Probabilities in Python
Since classical probability is mostly about counting, it makes sense that Python’s standard library Counter class should play a role. Also, since probabilities are fractions, it makes sense to represent them using Python’s standard library Fraction class.
from fractions import Fraction
from collections import Counter
import itertools as it
import random
from enum import Enum
Here’s a way to represent the possible outcomes of a six-sided die roll.
d6 = Counter(range(1,7))
d6
Here’s a fair coin.
coin = Counter({'H', 'T'})
coin
The classical probability
def prob(event, space):
"""Classical probability."""
return Fraction(len(set(event) & set(space)), len(space))
Here’s the probability of rolling a 2 on our (mathematical) six-sided die.
prob({2}, d6)
And here’s the probability of rolling an even number.
prob({2, 4, 6}, d6)
As expected, the probability of landing heads on a fair coin is
prob({'H'}, coin)
We can write a Python function to determine whether an outcome is in some event of interest. This will be useful when we are dealing with large sample spaces and more complicated events. Here’s how to do it for a simple example.
def is_even(n):
return n % 2 == 0
We can write another function to generate all the outcomes in the sample space that satisfy the condition we’re interested in for the event (in this case, that the die roll is even).
def such_that(condition_true_for, space):
"""Subset of sample space for which a condition is true."""
return {element for element in space if condition_true_for(element)}
such_that(is_even, d6)
So now we have two possible ways to specify an event: an explicit set of outcomes (e.g., {2, 4, 6}) or via a function, which will generate the event for us based upon a condition we care about. The function approach is what we’ll mostly use since it scales up to large numbers of outcomes very easily.
We can now modify our probability function to accept the event either as an explicit set or via a function.
def prob(event, space):
"Classical probability (revised version)."
if callable(event):
event = such_that(event, space)
return Fraction(len(set(event) & set(space)), len(space))
prob(is_even, d6)
We can also use Python’s lambda expressions to define “anonymous” functions, which work well for simple conditions.
prob(lambda n: n > 4, d6)
Here is a good tutorial on Python lambda expressions if you haven’t encountered them before. They can be useful for short, simple functions like the example above. If you need to do anything more complicated, it’s better to write a normal Python function and pass it in to the prob() function.
Modeling Poker Hands in Python
Now let’s do something a bit more challenging, and analyze some five-card poker hands. Let’s define the suits (clubs, diamonds, hearts and spades) and ranks (deuce through ten and the face cards.)
SUITS = 'cdhs'
RANKS = '23456789TJQKA'
Note that I used “T” for the ten, in order to use only one character for each of the ranks. It will also be useful later to have a way to map face cards to a numerical value, so we can compare them with the non-face cards.
RANK_VALUES = {rank: 2+RANKS.find(rank) for rank in RANKS}
RANK_VALUES
Now, let’s define the deck. The deck is all possible ordered pairs (rank, suit), for each of the ranks and suits. The mathematical term for this is the Cartesian product of the ranks and the suits. We can generate the Cartesian product using product() from Python’s built-in itertools package. The results of the product() function actually are in the form of a tuple (to be precise, an iterable of tuple), but let’s just concatenate the rank and suit characters to make a two-character card label for simplicity.
def standard_deck():
"""Make a standard French deck (no jokers)."""
return [r+s for r, s in it.product(RANKS, SUITS)]
deck = standard_deck()
len(deck)
Let’s take a look at the first 10 cards in the deck.
deck[:10]
The deck is currently in order sorted low to high by rank and suit. Let’s draw a random hand of five cards from our deck.
random.sample(deck, 5)
The above keeps the deck in order, but it is choosing five cards deck for you at random as though you had shuffled it. You could also achieve the same effect by explicitly shuffling the deck, and taking the “top” five cards.
random.shuffle(deck)
hand = deck[:5]
hand
Now let’s generate all possible five-card poker hands. To do this efficiently, let’s use combinations() from itertools to generate all possible ways we can create a five-card hand, where the ordering of the cards in the hand doesn’t matter.
def possible_five_card_hands(deck):
"""Possible five-card poker hands from a standard deck."""
return it.combinations(deck, 5)
hands = list(possible_five_card_hands(deck))
len(hands)
As mentioned above, there are almost 2.6 million possible five-card hands to analyze.
Now we can begin our analysis of five-card poker hands. Let’s build a series of small functions that will give us the basic information about the cards in a hand.
def rank(card):
"""The rank of a card."""
return card[0]
def suit(card):
"""The suit of a card."""
return card[1]
def ranks(hand):
"""Counter of different ranks in a hand."""
return Counter([rank(card) for card in hand])
ranks(hand)
def suits(hand):
"""Counter of different suits in a hand."""
return Counter([suit(card) for card in hand])
suits(hand)
Now let’s define the possible types of five-card poker hands. We can create an enumeration using Python’s built-in Enum class to keep track of the relative value of the hands.
class FiveCardHand(Enum):
"""Types of five-card poker hands ordered ascending by hand strength."""
NOTHING = 0
ONE_PAIR = 1
TWO_PAIR = 2
THREE_KIND = 3
STRAIGHT = 4
FLUSH = 5
FULL_HOUSE = 6
FOUR_KIND = 7
STRAIGHT_FLUSH = 8
ROYAL_FLUSH = 9
Now, let’s start to look at hands that have multiple cards of the same rank (i.e., pairs, three of a kind, full house and four of a kind). Analysis of these hands ignores the suit of the cards.
Python’s Counter class gives us the method most_common() which makes it easy to count groups. Our ranks function already returns a Counter based upon the ranks in the hand. All we need to do is get the two most common groups of ranks. Then, we can figure out the type of hand by looking at the counts of the most common group of ranks and the next most common group of ranks.
def rank_groups(hand):
"""Counts of the most common and next most common ranks of a hand."""
most, next_most = ranks(hand).most_common(2)
# most_common() returns tuples of (item, item_count)
# we only want the count
most = most[1]
next_most = next_most[1]
if most == 2 and next_most == 1:
return FiveCardHand.ONE_PAIR
elif most == 2 and next_most == 2:
return FiveCardHand.TWO_PAIR
elif most == 3 and next_most == 1:
return FiveCardHand.THREE_KIND
elif most == 3 and next_most == 2:
return FiveCardHand.FULL_HOUSE
elif most == 4:
return FiveCardHand.FOUR_KIND
else:
return FiveCardHand.NOTHING
Now let’s look at the slightly more complicated situations of straights and flushes. A flush is a hand that has all cards of the same suit. A straight is a hand that has the cards in sequence, although you need to keep in mind that aces can be either low (i.e., below the deuce) or high (i.e., above the king). Furthermore, we need to keep distinct from normal straights and flushes the straight flush (a hand this is both a straight and a flush) and a royal flush (a hand that is a straight, a flush and runs ten through ace).
Let’s start off by defining a simple function that will tell us if all the cards in the hand are of the same suit.
def are_same_suits(hand):
"""True if the hand has all cards of the same suit."""
return len(set([suit(card) for card in hand])) == 1
Now let’s figure out how to see if all the cards in a hand are in sequence. There aren’t that many distinct sequnces, so let’s just build a set of them once and for all, so we can quickly check a given hand.
RANK_SEQUENCES = {RANKS[i:i+5] for i in range(9)}
RANK_SEQUENCES.add('2345A') # Ace-low straight
RANK_SEQUENCES
Notice that the above set includes the ace-low situation. Now, using this set, it’s very easy to check if a given hand is in sequence. We simply sort the cards by rank value, and see if the hand is in the set of valid sequences.
def is_in_sequence(hand):
"""True if the hand has all ranks in sequence, ignoring suit. Aces can be high or low."""
ranks = ''.join(sorted([rank(card) for card in hand], key=lambda card: RANK_VALUES[rank(card)]))
return ranks in RANK_SEQUENCES
Now we can put everything together to write a function to figure out the hand type.
def five_card_hand_type(hand):
"""Type of five-card poker hand."""
hand_type = rank_groups(hand)
if hand_type != FiveCardHand.NOTHING:
return hand_type
if are_same_suits(hand):
if is_in_sequence(hand):
if all(rank(card) in 'TJQKA' for card in hand):
hand_type = FiveCardHand.ROYAL_FLUSH
else:
hand_type = FiveCardHand.STRAIGHT_FLUSH
else:
hand_type = FiveCardHand.FLUSH
elif is_in_sequence(hand):
hand_type = FiveCardHand.STRAIGHT
return hand_type
def is_five_card_hand_type(hand, hand_type):
"""True if a hand is a given type of five-card poker hand."""
return five_card_hand_type(hand) == hand_type
Let’s compute the probability of possible five-card draw hands, and compare the results to the probability of the hands from Wikipedia. Note that Python’s Fraction class will reduce the fraction to lowest terms, so to make comparison easier I’ve shown the Fraction applied to the frequencies from the Wikipedia page, with a denominator equal to the number of possible hands.
Royal Flush
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.ROYAL_FLUSH), hands)
# Probability of royal flush from Wikipedia
Fraction(4, 2598960)
Straight Flush
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.STRAIGHT_FLUSH), hands)
# Probability of straight flush from Wikipedia
Fraction(36, 2598960)
Four of a Kind
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.FOUR_KIND), hands)
# Probability of four of a kind from Wikipedia
Fraction(624, 2598960)
Full House
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.FULL_HOUSE), hands)
# Probability of full house from Wikipedia
Fraction(3744, 2598960)
Flush
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.FLUSH), hands)
# Probability of flush (excluding royal flush and straight flush) from Wikipedia
Fraction(5108, 2598960)
Straight
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.STRAIGHT), hands)
# Probability of straight (excluding royal flush and straight flush) from Wikipedia
Fraction(10200, 2598960)
Three of a Kind
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.THREE_KIND), hands)
# Probability of three of a kind from Wikipedia
Fraction(54912, 2598960)
Two Pair
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.TWO_PAIR), hands)
# Probability of two pair from Wikipedia
Fraction(123552, 2598960)
One Pair
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.ONE_PAIR), hands)
# Probability of one pair from Wikipedia
Fraction(1098240, 2598960)
Nothing
prob(lambda hand: is_five_card_hand_type(hand, FiveCardHand.NOTHING), hands)
# Probability of nothing (high card) from Wikipedia
Fraction(1302540, 2598960)
Everything checks out. We’ll stop here for now, but there’s a lot more to say about probability in upcoming posts. This post only looked at random processes with equal probabilities for each outcome in the sample space. We’ll see in future posts how easy it is to use Python’s Counter class to handle more general situations. We’ll also build much more useful Python tools to take advantage of that flexibiilty. But even with the few dozen lines of code in this post, we were able to quickly build some tools to help us analyze poker hands.
Some Closing Thoughts
The poker analysis illustrates the pros and cons of simple but brute force computing power, compared to detailed mathematical analysis. If you look at the Wikipedia page for the frequency of five-card poker hands again, you’ll see in the far-right column detailed formulas for the frequency of each hand. Unless you’ve studied some combinatorics, these formulas probably won’t make much sense. The point is that is possible to solve these poker probabilities “by hand”, if you reason carefully about the number of ways a given hand can occur. Combinatorics is the advanced mathematical analysis of counting, and is used in many fields, including computer science.
Mathematical analysis is powerful and elegant, but can be tricky. The advantage of the straightforward approach taken here is that it’s hard to make a mistake. Other people can also quickly understand your method just by reading the code. Ideally, the best approach would combine the benefits of both mathematical analysis and the smart application of computing power. We could have made our code run faster, for instance, by recognizing that it does a lot of duplicate work. The probability calculation essentially checks every possible hand, for every possible hand type.
As an example, to count flushes, we don’t care what suit the hand is in, as long as all cards are in the same suit. To speed things up, we could have worked with a deck of only one suit, and counted up all the possible flushes in that one-suit deck. Then, we would just multiply by 4 to get the number of flushes in the true deck.
The code we wrote works fine for the five-card analysis here, especially since this an analysis we only need to run once. If we needed to recompute probabilities frequently (to update a win probability during a sports event, for instance), we would care a lot more about speed. For problems with much larger sample spaces, we would almost certainly need to be smarter, to avoid having our code run out of computer memory or run too slowly.