
In this post, we will look at coin flips to see how to analyze outcomes which depend on more than one source of randomness. These are called joint events and have joint probability distributions. We will see how you combine the probabilities of simpler events to create joint probabilities by multiplication.
A Jupyter notebook with the code and portions of the text from this post may be found here.
This post uses the pracpred package introduced in the previous post on probability distributions. If you haven’t already installed this package in your sports analytics environment, the following Jupyter Notebook command will install it for you.
%%capture
import sys
!{sys.executable} -m pip install pracpred
You can also run the command pip install pracpred in your Terminal (Mac or Linux) or in Anaconda Prompt (Windows). Let’s import the packages we are going to use in this post.
import pracpred.prob as ppp
from collections import Counter, OrderedDict
import numpy as np
import pandas as pd
pd.options.display.float_format = '{:.5e}'.format
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
sns.set_context('notebook')
plt.style.use('ggplot')
Fair Coins
A coin can land heads or tails, signified by H and T respectively. Here’s a model of a fair coin.
fair_coin = ppp.ProbDist({'H', 'T'})
fair_coin.name = 'fair coin'
print(fair_coin)
The probabilities of each outcome are automatically set to 
Biased Coins
However, if you want to represent a coin biased to land heads more often than tails, you can do that very easily. For example, here is a model of a coin with a 
biased_coin = ppp.ProbDist(H=5, T=4)
biased_coin.name = 'biased coin'
print(biased_coin)
Two Coin Flips
If you flip the fair coin twice, there are four possible outcomes. The four outcomes are HH, HT, TH and TT. Notice that HT is a different outcome from TH. In this framework, the order of the flips matters.
We will assume as usual that the coin flips are independent, since there is no reason to believe that the first flip should physically affect the other. All the outcomes are still equally likely, so they should each have probability 
fair_coin + fair_coin
Another way of thinking about this experiment is that we have two fair coins that we are going to flip at the same time, but we can tell them apart. Maybe the coins are of two different types, but they are both fair. Under this interpretation, HT is still different from TH. However, rather than ordering the flips, the first character represents coin 1 and the second character represents coin 2.
Now suppose that coin 1 is fair, and coin 2 is biased. What is the distribution of the outcomes?
The two coin flips are still assumed to be independent. There’s no physical reason to think that the bias of coin 2 impacts the result of flipping coin 1. There are still four possible outcomes, but they aren’t equally likely any more.
We can figure out the answer by using a simple thought experiment.
Ping Pong Balls in a Box
Imagine we are going to represent our outcomes as plain white ping pong balls.
We want each ball to represent a possible outcome, but reflecting the correct probability that the outcome happens. How many balls do we need to have inside the box to represent our flip of the fair and biased coin?
For the biased coin, the probability of heads is
For the fair coin, in theory we only need 2 balls, of which one would represent heads. We can have more than 2 balls though. Any even number would do. Half would represent heads, and the other half would represent tails. Since 18 is an even number, 18 balls works for the fair coin as well. Of these 18 balls, 9 would represent heads of the fair coin.
A Thought Experiment
Here comes the thought experiment. We have 18 plain white ping pong balls. Paint 10 of them blue on one-half of the ball. These represent the heads of the biased coin. It doesn’t matter which 10 plain white balls we pick for this step. The other 8 balls are still plain white.
After the blue paint dries, take half of the plain white balls, and paint them red on one-half of the ball. That’s 4 balls now half-red, with the other half white. Now take half of the 10 balls half-painted blue, and paint the other half of those balls red. That’s 5 balls half-red, half blue.
There are 
After the paint dries, put the balls back inside a box that we can’t see through. The event that both coins land heads is just the outcome that we pick a random ping pong ball out of the box and it comes up half-blue, half-red. How many balls (out of the 18 total balls) are painted this way? We already know the answer is 5.
Picking ping pong balls at random out of a box is back in the world of equally probable outcomes. We assume that the paint color doesn’t impact our random choice of ball since we can’t see the paint and we can’t tell the difference between the balls without looking at them.
Since there are 5 half-blue, half-red ping pong balls, the probability of drawing one of those balls is 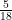
The Multiplication Rule for Probability
It may have been obvious all along, but the rule for independent events is just to multiply the probabilities of each event. If we have two independent events 

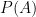
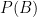

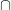
Here is a simple visualization for the fair and biased coin flips. The red area represents heads on the fair coin, and the blue area represents heads on the biased coin. The overlapping purple area is where both coins are heads. The unshaded area is where both coins are tails. If you change the coin probabilities, you can run the code below and it will adjust the shaded areas automatically.
def plot_coins(coin1, coin2):
fig, ax = plt.subplots(figsize=(6,6))
ax.set_aspect('equal')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
coin1_heads = plt.Rectangle((0, 0), float(coin1['H']), 1, color='r', alpha=0.2)
coin2_heads = plt.Rectangle((0, 0), 1, float(coin2['H']), color='b', alpha=0.2)
ax.add_artist(coin1_heads)
ax.add_artist(coin2_heads)
ax.set_xlabel(f'{coin1.name}: red = P(heads)')
ax.set_ylabel(f'{coin2.name}: blue = P(heads)')
ax.set_title(f'flip both {coin1.name} and {coin2.name}: purple = P(both heads)')
start, end = ax.get_xlim()
plt.xticks(np.arange(0, 1.001, 0.1))
plt.yticks(np.arange(0, 1.001, 0.1))
plt.show()
plot_coins(fair_coin, biased_coin)

To discover the multiplication rule, we assumed that the coin flips were independent events. It turns out there is a more general result that applies for dependent events as well, but we will set that aside for the time being.
The ProbDist class can compute the joint probability of independent events automatically for you.
fair_coin + biased_coin
If you look at the probabilities in the above distribution, you will see that they match the areas in the plot immediately above.
Playing with Biased Coins
Now, let’s pretend that we don’t know which coin is biased or by how much, but we’re told that one of them is biased. We don’t have enough information to compute the probabilities of each outcome anymore. Even so, we can learn something interesting by grouping the HT and TH outcomes together.
def ignore_order(flips):
return ''.join(sorted(flips))
(fair_coin + biased_coin).groupby(ignore_order)
As long as we are sure one coin is fair, the outcome where one coin is heads and the other tails always has probability
Fair Coins from Biased Coins
The great mathematician John von Neumann actually took this a step further to come up with a way to always get perfectly fair coin flips, even if you only have a biased coin.
The procedure is simple. Just flip a biased coin twice, and only look at outcomes where one flip lands heads, and the other flip lands tails. If you get HH or TT, ignore the results and do two more flips until you get either HT or TH.
biased_coin.repeated(2)
def different_flips(flip):
return len(set(flip)) > 1
Now, just call HT “heads” and TH “tails.
(biased_coin + biased_coin).such_that(different_flips)
To see why this works, look back at the probability distribution for 2 flips of the biased coin. Both 
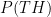
Another way to see why this works is as follows. The probability of HT is:

This is true because each coin flip is independent. Similarly, the probability of TH is:

This is true because multiplication is commutative: the order doesn’t matter. Since we can tell the difference between the outcomes HT and TH, but they have the same probability, we can pretend that one is “heads” and the other “tails” from a fair coin. You can read more about this here.
Even if your coin is very biased, this procedure still works.
very_biased_coin = ppp.ProbDist(H=0.9, T=0.1)
very_biased_coin.name = 'very biased coin'
very_biased_coin.repeated(2)
very_biased_coin.repeated(2).such_that(different_flips)
The only problem is that you might have to wait a while to get HT or TH, if one or both of the coins are very biased. In a later post, we’ll see how to figure out how many flips you should expect to wait before you get HT or TH for biased coins.
Here’s a plot of the probability distribution for joint flips of the biased and very biased coins.
plot_coins(very_biased_coin, biased_coin)

Coin Flipping Experiment
Let’s finish up by showing how to generate random coin tosses from our fair and biased coins. We’ll start by computing the theoretical probabilities we expect to get. Then we’ll simulate thousands of results from the probability model and compare to the theoretical probabilities.
Let’s focus on the number of heads we get if we flip a coin 12 times.
FLIPS = 12
len(fair_coin.repeated(FLIPS))
There are 4096 possible outcomes for each experiment.
list(fair_coin.repeated(FLIPS).items())[:10]
The flips are assumed to be independent. Also, we only care about the number of heads, not the order. So, we can summarize the outcomes by number of heads.
def number_of_heads(flips):
return flips.count('H')
fair_heads_dist = fair_coin.repeated(FLIPS).groupby(number_of_heads)
fair_heads_dist.name = 'fair heads pmf'
print(fair_heads_dist)
Summarizing by number of heads reduces the sample space to the numbers between 0 and 12. Let’s compute the same probabilities for the biased and very biased coins.
biased_heads_dist = biased_coin.repeated(FLIPS).groupby(number_of_heads)
biased_heads_dist.name = 'biased heads pmf'
very_biased_heads_dist = very_biased_coin.repeated(FLIPS).groupby(number_of_heads)
very_biased_heads_dist.name = 'very biased heads pmf'
Let’s look at the probability mass functions for each coin assuming we run the same experiment of 12 coin flips.
pmf = pd.DataFrame(OrderedDict({
dist.name: [float(dist[i]) for i in range(FLIPS+1)] for dist in [
fair_heads_dist,
biased_heads_dist,
very_biased_heads_dist,
]
}))
pmf
Since we have some very small numbers for these probabilities, we’re using scientific notation in the table so you can see all the numbers to equal precision. If we didn’t use scientific notation, you’d see a lot of zeroes in the table for the very biased coin.
As a check, let’s make sure the PMFs all sum to one for each coin.
pmf.sum()
Visualizing Probability Mass Functions
Let’s plot these PMFs so we can visualize the differences between the coin outcomes.
x1, y1 = fair_heads_dist.zipped
x2, y2 = biased_heads_dist.zipped
x3, y3 = very_biased_heads_dist.zipped
fig, ax = plt.subplots(figsize=(10,5))
width = 5/len(x1)
ax.bar([x-width/2 for x in x1], y1, width, alpha=0.5, label=fair_heads_dist.name)
ax.bar([x for x in x2], y2, width, alpha=0.5, label=biased_heads_dist.name)
ax.bar([x+width/2 for x in x3], y3, width, alpha=0.5, label=very_biased_heads_dist.name)
ax.set_xticks(x1)
ax.set_xlabel('number of heads')
ax.set_ylabel('P(number of heads)')
ax.set_title(f'distribution of {FLIPS} coin flips')
ax.legend(loc='upper left')
plt.show()

The fair coin distribution is symmetric but the biased coins are skewed to the right. The very biased coin distribution is extremely skewed.
Simulating Coin Flips
Now we will generate a simulation of random coin flips for each of the three coins.
In a future post, we’ll use this type of simluation to build a simple prediction model for tennis.
Here’s how to generate a random set of independent coin flips.
flips = biased_coin.choices(FLIPS)
flips
Now we can generate a large number of trials (in this case, 10,000) for each experiment. Again, the experiment is flipping the coin 12 times and counting up the number of heads.
def flip(coin, summarize, per_trial, trials):
return [summarize(coin.choices(per_trial)) for _ in range(trials)]
TRIALS = 10_000
fair_heads = flip(fair_coin, summarize=number_of_heads, per_trial=FLIPS, trials=TRIALS)
len(fair_heads)
The average number of heads per experiment is about 6, which is reasonable for a fair coin. Remember, this average is over 10,000 trials.
sum(fair_heads)/len(fair_heads)
Now let’s do the same thing for the biased and very biased coins.
biased_heads = flip(biased_coin, summarize=number_of_heads, per_trial=FLIPS, trials=TRIALS)
very_biased_heads = flip(very_biased_coin, summarize=number_of_heads, per_trial=FLIPS, trials=TRIALS)
sum(biased_heads)/len(biased_heads)
sum(very_biased_heads)/len(very_biased_heads)
The average number of heads for the biased coin is higher than 6, but still relatively close. The average for the very biased coin is almost 11.
Now let’s build a table of the frequency of all the outcomes for each coin experiment. The frequency is just the count of each outcome (number of heads) divided by the total number of trials.
def frequency(outcomes, force_len=None):
c = Counter(outcomes)
if force_len: # include zeroes up to the specified number of outcomes
for i in range(force_len+1):
if i not in c:
c[i] = 0
return {n: x/sum(c.values()) for (n, x) in c.items()}
EXPERIMENT = {
'fair freq': fair_heads,
'biased freq': biased_heads,
'very biased freq': very_biased_heads,
}
freq = pd.DataFrame(OrderedDict({
outcomes: frequency(EXPERIMENT[outcomes], force_len=FLIPS) for outcomes in EXPERIMENT
}))
freq
The sum of the frequencies had also better be 1, since we divided all the counts by the number of trials in each experiment.
freq.sum()
Comparing the Frequencies and the Probabilities
If we can run an experiment a large number of times, the relative frequency of an outcome should be close to the probability of that outcome. The relative frequency is just the number of trials having that outcome, divided by the total number of trials in the experiment.
In fact, in the Frequentist view of probability, the definition of probability is just the limit of relative frequency as you imagine doing more and more trials in the experiment.
Let’s put the theoretical probabilities and observed frequencies for each coin flipping experiment in a table. Hopefully, the observed frequencies are reasonable compared to the theoretical probabilities.
df = freq.merge(pmf, left_index=True, right_index=True)
cols = sorted(df.columns)
df = df[cols]
df
The observed values look reasonable compared to the probabilities, so our code seems to be working. Of course, the observed frequencies don’t exactly equal the probabilities. Notice, for example, on the very biased coin, that we didn’t get fewer than 6 heads on any trial. As you can see in the rightmost column, the probability of getting 5 heads is a little less than 5 parts in 100,000. So it’s not very surprising that we didn’t see the outcome 5 heads in our experiment. If we increased the number of trials to 100,000, we would expect to see at least a few trials with 5 heads.
One important thing to keep in mind is that we’re doing this “experiment” on a computer, using the random number generators that are available with Python. In the real world, the randomness of coin flips comes from how the coin rotates in the air, and what happens if and when it is allowed to hit a hard surface. We are assuming that our computer-generated randomness is a good approximation to “real” randomness. This is an important topic, which we may return to in later posts. In the meantime, if you’re curious, here’s a brief article about how computers deal with random numbers.